Julian's Home Page
Thanks for visiting my homepage, even if you arrived here by accident!
 |
 |
I make no apology for the bizarre ordering on this page, which I use mainly as an aide-memoire for myself!
I am a Member of the Professional Staff and a Principal Computational Scientist at Caltech, where I currently work in the Seismolab on computing for seismology and earthquake early warning, under a Cooperative agreement with the USGS. I am a Fellow of the UK Institute of Physics. Prior to joining Caltech in 1997, I held a staff position as a physicist at CERN in Geneva, Switzerland, where I worked on the CMS (LHC) and Aleph (LEP) experiments. Prior to that I was at the Max Planck Institute in Munich, working on the NA24 experiment, followed by a time working on the UA1 experiment for the Rutherford Appleton Laboratory in Oxford. I have a Ph.D. in Particle Physics from the University of Sheffield, and a B.Sc. in Physics from the University of Manchester.
Current Activities
My work with the USGS is in the area of computing for seismology and earthquake early warning. I contribute to developments of the ShakeAlert system, especially the PLUM algorithm for shaking predictions from the propagation of observed ground motion, and distributed sensor networks for seismic event detection deployed in Costa Rica and in the Lake Tahoe region of the USA. I also work on the IPAWS interface to ShakeAlert used for public early warning.I continue to maintain the software I developed for Caltech's Community Seismic Network (CSN), a project I have been a member of since 2011.
Contents
A full linked listing of the contents of this website is here.
Publications
Please see my list of publications (updated March 2024).
Recent Activities
Sensor networks for medicine, radiation detection, and seismic event detection, algorithms for electric power distribution, botnet traffic analysis. Applications of ML to observed scientific data using supervised and unsupervised learning. Taught classes on databases, distributed and cloud computing, sensor networks for hazard detection, eScience, genetic algorithms, and other CS topics. Mentored SURF students over many years.
AudioTool Interview
I was recently (2023) interviewed by Matevz Leskovsek of irzu.org about my Android app "AudioTool" for acoustic measurements.
CyberSecurity
Animation of the growth of Botnet traffic on a LAN.
2017 Announcement of opportunity to work on Botnet Detection.
Coursera Courses
The main Caltech Coursera web page.
This is my short introduction to Practical Genetic Algorithms, part of the Caltech-JPL Summer School on Big Data Analytics. (Both links currently down while Caltech migrates its content to the new Coursera system.)
Sonification
A proposal from 2009 that incorporates sonification of scientific data, entitled "Audiovisual cueing of significant events in large multivariate science and security datasets".
Pervasive Computing for Disaster Response
This was an NSF-funded project, in collaboration with UC Irvine and IIT Gandhinagar, India. See the projec t website here.

The Community Seismic Network is a related project.
Sandra Fang, a Caltech SURF student in 2012, built a "Home Hazard Weather Station" - check out her blog here. This is a photo of the completed prototype, which contains sensors for dangerous gasses such as CO and LPG, acceleration, barometric pressure, humidity, sound, light, and radiation (using a Geiger counter).

Judy Mou, a Caltech CS student, is now building a situation awareness Android app for a tablet and/or Google TV, that takes the sensor data from the Hazard Weather Station and combines it with a dynamically updated collection of regional environmental, hazard and news information.
There is a SURF Announcement of Opportunity to work on this project in 2013.
Voynich Manuscript
My guide to the Voynich Manuscript is now available on Amazon.
Cellphone Medicine
A report from Theresa Juaraz describing her SURF work on medical sensors: Rugged encapsulation structures and acoustic instrument development for inexpensive medical sensors
SURFers Develop Cell-Phone Medical Devices
I'm working with Prof. K. Mani Chandy on various aspects of using cellphones as sensing devices, and in particular as first response medical tools. Here's a proposal we submitted to the Gates Foundation.
This is our idea for a 10c Medical Checkup.
Here is a presentation by Victor Chu and Aleksander Palatnik, two SURF students who worked with us on this project over the Summer 2009.
Old MWPC Data from Georges Charpak
In the late 80s, when I was a junior member of staff at CERN in the computing division, I worked briefly on some multiwire proportional chamber (MWPC) data that Georges Charpak needed to have rendered as graphics. I used an Apollo workstation (See http://en.wikipedia.org/wiki/Apollo_Computer) running in "borrowed mode" (whereby the application had access to the whole screen of the device). Charpak's data was of the head, chest and pelvis of one (or more?) patients, and came in three files: heglo1, kulin1, and tihon2. I do not recall what these names signified. I can remember Charpak getting quite excited when he saw the images! These data may possibly have some historical significance (I have been unable to find an email address for Charpak to ask him), so I have zipped them up, together with example Fortran code I wrote for decoding them, in the archive here for posterity.
AIRR, WinAIRR, Synthesizers, Minisonic, Electronics, Sound, Video and Electronics
|
Sony CDP-X555ES High End CD Player (1991)
|
|
|
Nakamichi RX-505 and RX-202 Cassette
Decks
|
|
|
Marantz SR 2000 Stereo Receiver
|
|
|
JVC Reverberation Amplifier ECA-102
|
|
|
Realistic 2-A Electrostatic
Speaker
|
|
| Software for handheld devices and mobile phones. | |
|
A Modular Analogue Sound
Synthesizer
This is a new project, started in October 2009 |
|
|
Minisonic2 Sound Synthesizer project. The photo below shows my completed Minisonic2 sound synthesizer, which follows Doug Shaw's original design published in Practical Electronics in the early 70s.
|
|
| A
selection of Analogue Sound
Synthesizers
|
|
My Nixie tube clock.I found a nice little box to put it in in a shop in France.
The biggest challenge was drilling the required 1" diameter holes (I ended up using a Forstner bit).
Here are the guts:
Here is the completed clock as installed in the sitting room, next to an
old writing cabinet. | |
| I think I inherited my interest in
electronics, radios, scopes etc. from my Dad, who is also
a physicist. My Dad and I went to buy my first scope from a surplus shop in South London ... when we got there, they had about a dozen ex-Navy Solartron scopes for sale. Of course, we only wanted one, and my Dad started going through each of them testing all the functions. By the time he got to the last one, we realised that not one of them was in perfect working condition: each had something that didn't work. However, the guy who owned the shop had one on his bench, the one he was using. My Dad said "Well, what about *that* one?!". Of course it worked perfectly, and that was the one I ended up with. But the real event that started my electronics interest off was buying an ex-GPO amplifier box from a surplus stall on St.Albans market. I have no idea why I bought it, or how little I paid, but when I got it home and opened it up, I was fascinated by all the little components, transistors, resistors, capacitors. It also had lots of knobs on it ... and I think this is a key attraction ... anything with a lot of knobs is by inherently very interesting. Because I wanted to know how the amplifier worked, I wrote a letter (I suppose I was about 12 years old) to the GPO. I told them the number on the box, said I wanted some details, and waited for a reply. A week or so later, a GPO post office van pulled up outside our house, and a postman came down the drive carrying an envelope. Inside was a letter from a Mr. Betton, and attached to the letter was the circuit diagram for the amplifier. I still have it. Even more wonderful: the postman returned to the van, opened up the back door, and fetched out a pile of Practical Wireless and Practical Electronics magazines, tied up in string, which he then gave to me. I still have all those magazines, dating from the early 60s through to the early 70s. A gift from Mr. Betton, who said he had no further use for them, and thought I might like them. That sort of helpful benevolence is a wonderful thing. | |
My Single Ended Stereo Tube Amplifier.Uses a 6SN7GT as a pre-amp, and doubled-up 6GF7A triodes as the power stage.
More details, including schematic, here. | |
A spectrum analyzer I made in about 1990.It was
built for 220 Volts mains, and included a 9V rectifier.
The audio input is fanned out into five separate bandpass filters of my
own design. Each filter is based around a 741 opamp, and tuned to a
different frequency from the rest. The output from each filter is fed to a
set of five LM341 LED driver ICs which each turn a bank of 10 LEDs on
depending on the output level. The 341 can run in two modes: the first mode
lights just the LED corresponding to the output voltage, the second lights
that LED and all below it. I had a switch to select between the two.
My design had several flaws, most serious was that there was interference
between the lowest two banks of LEDs. I think the filters are very wide, and
I was too ambitious in tuning their centre frequencies. The result is that,
for low frequency inputs, the lowest LED banks oscillate in brightness. | |
Vacuum Tubes / ValvesTable of the my vacuum tubes (or valves). Here is the spreadsheet. Table of my transistors. Here is the spreadsheet.
| |
Precision Tube TestersA web page devoted to the various models of Tube Testers made by the Precision Apparatus Corporation, who were eventually bought up by B&K Instruments Here's a picture of my Precision 660 ... this is different from all other 660s I've seen in that it has more transistor and tube sockets. I refurbished the case, since the original cloth-like covering was very tatty. To do this I removed all the material, sanded down the surfaces, and applied three coats of Danish Oil.
More pictures here, including showing the instrument testing a 6SN7GT dual triode: (click on thumbnails for larger versions)
|
Lloyd's Solid State 5 Band Receiver
Ebay: $4.99 9H34W-34A five band receiver. The five bands are:
|
Tektronix OscilloscopesTake a look at my collection of Tektronix oscilloscopes and Plug Ins. Look at the knob count on this baby - my Tektronix 556 Dual Beam 'scope.
Here's an image of the 556 in use, testing the Minisonic2
My 214 mini storage 'scope
Here's my 310A, 516, 5441, 561A, 321A, 310 and 575 curve tracer
The 7D20 plugged in to my 7904 mainframe:
Full details on all these Tektronix scopes is here. Here's a TS-34A military 'scope dating from 1953, in working condition. I have the original manual for this 'scope: the scan is here.
Here's my Telequipment S-43. There are two other plugins for this 'scope in my collection.
|
Solartron OscilloscopeThis is a pic of a Solartron 'scope identical to one I had as a boy. I believe these were used by the British Navy. I cannot recall the model number, but it was perhaps an OS-20?
My dad and I drove down to Dartford (South London) to buy
it. When we arrived, the guy had around six
for sale, and another he was using on
his workbench for himself. My dad and I checked
each of the |
MJS Sweep Marker Generator
| |
Hewlett Packard 608C VHF Signal Generator
Above picture shows the generator as received. Below shows the generator after repainting, face cleaning etc.
Look at the engineering inside (there are several belts and pulleys)
I checked the performance using my Leader digital frequency meter: the 608C produces beautiful sine waves and is accurate up to at least 90Mhz (the limit of the Leader). The front panel meters correctly show the modulation and output signal levels. Somebody said that by using the analogue modulation input on the 608C it would be possible to broadcast video to a nearby TV! The manual for the 608D (very similar to the 608C, but features a crystal marker) is here.
| |
| A Non Linear Systems
Miniscope, model MS-15. Ebay: $18
The manual for the similar MS-230 is here (it is also on BAMA). Thanks to Marvin Moss. Here is the schematic for the MS-15. And another version.
| |
| Here's a UEI Oscilloscope,
model 301. It has sweep ranges of 30-500Hz, 500-5kHz, 5khz to 100kHz. This
cost me $1.00 on Ebay :-)
| |
|
Transistor TesterMy SECO Transistor and Tunnel Diode tester, Model 250.
|
Resistance/Capacitance TesterMy Knight R/C checker came with a 6E5 Magic Eye tube. Here's an animated GIF of the tube as the checker moves through the correct measured resistance value:
|
Allied Knight R100 Communications ReceiverThis communications receiver, dating from about 1957, includes an S-meter and crystal calibrator.
More details here. |
| My
Hallicrafters
Communications Receivers (an SX-110, SX-71, S-107, S40A, WR600, SX-130,
SX-62, 5R10A, 5R100A, SP-44, SX-62) See here for more details. SX-71 (Run4):
SX-28:
SX-110:
SP-44:
R-46:
SX-71 (Run3):
S-107:
S-40A:
WR-600:
5R10A:
SX-130: 5R100A:
| |
| Hammarlund HQ-110C | |
WinAIRR and AIRR (Anechoic and In-Room Response)An article published in Speaker Builder Magazine describing AIRR, software for measuring loudspeaker response using a SoundBlaster card. The more recent version for Windows: WinAIRR. | |
| An article published in Speaker Builder Magazine on the subject of PC-based sound. | |
| An advert from Practical Wireless, early 60s, showing the Wharfedale Column Speaker, constructed from a concrete pipe. My father made two of these and they sounded very good! | |
| A program that generates Maximum Length Sequences, and for each MLS cyclically autocorrelates it to demonstrate its special property. MLS is used in acoustic measurement. It has a number of advantages over pulse-based measurements. Here is some pseudo-code that implements MLS and the Fast Hadamard Transform (FHT) to make the calculation much faster .... Contact me if you have questions ... | |
| A tool for plotting the frequency decomposition of the sounds in a Windows WAV file. | |
| Some code for manipulating the Windows Mixer. | |
| Simulated sound of an instrument that monitors the collapse of binary stars into one another (it's big). | |
| A presentation made to the CMS Software and Computing Board in November 1996, showing a selection of audio/video conferencing tools for Windows'95. | |
| Some stuff on MBONE unicast routing proposed in 1994, but now outdated. | |
| The Windows port of vic, one of the LBL videoconferencing tool suite. | |
| JJB is a member of the Audio Engineering Society | |
| Some code ( captjb.asm (Assembler) pmsj.c (C) getbuff.for (Fortran) ) for decrypting Videocrypt by rotating and matching scanlines. This was developed in 1994 for use with a Media Vision Pro Movie Spectrum video grabber card. | |



























































A Selection of Research Proposals
| Physics Lambda-based Network System (PLaNetS) Proposal |
| Global Information Systems and Network Efficient Toolsets (GISNET) Proposal |
| The UltraLight Project |
| The Global Grid-Enabled Collaboratory for Scientific Research (GECSR) to NSF, 2004 (and in PDF) |
| The FAST Proposal to NSF, 2003 |
| The CAIGEE Project (NSF Funded) |
| The international Virtual Data Grid Laboratory (iVDGL) |
| Immersed boundary model of the Cochlea (inner ear) with Ed Givelberg |
| Accessing Large Data Archives in Astronomy and Particle Physics (ALDAP), |
| Globally Interconnected Object Databases , |
| Grid Physics Network (GriPhyN) |
| Models of Networked Analysis at Regional Centres (MONARC), |
| Compact Muon Solenoid (CMS), |
| RD45 |
| Continuum Computing Architecture (CCA) (also known as the Simultac Fonton) with Thomas Sterling |
| Lisp-based Beowulf Scientific Inference Engine with Thomas Sterling and Roy Williams |
| Distributed Simulation Infrastructure for K12 with Tom Gottschalk and Sharon Brunett |
| Relational and Analysis Visualisation Engine with Roy Williams and Santiago Lombeyda |
| Distributed Teravoxel Data System with Paul Dimotakis et al. |
Cars Owned and Sold
Currently enjoying a Mercedes Benz SLK320 from 2002. This sports a 6 cylinder engine making 220 bhp. You can see the other cars I considered before deciding on the SLK by visiting my Pinterest board.

Previously: Jaguar E-Type, Porsche 911, Porsche 914, Triumph TR6, MGB GT here.
Holidays
Here is where we like to go on holiday

Patents
"Method and apparatus for dynamically directing an application to a pre-defined multimedia resource" - US Patent # 20020156870, issued 10/24/2002
Thesis
JJB's thesis (1983) roughly converted from Waterloo Script to HTML
Analysis and Visualisation (old)
| The HEPVIS'96 workshop on HEP data visualisation and analysis. |
| The PAW(Physics Analysis Workstation) is a software system used in the High Energy Phyics community for visualising and processing large quantities of experimental data. |
| A presentation of PIAF, the parallel version of PAW, describing the hardware and software configuration used for this multi-GByte capable analysis farm. |
| The programme of work of the Data Analysis Techniques section in CN Division, for 1996. Presented at the CN POW Meeting in Yverdon. |
| An Evaluation of PAW, presented at the HEPVIS'96 workshop (see above). |
| A description of the KUIP2TCL package, intended to assist porting of KUIP-based GUIs to Tk/Tcl. This was originally scheduled for inclusion in CERNLIB, but priorities changed ... |
Multimedia Archives of JJB
A selection of photographs.
Video of a talk I gave at the JHU eScience workshop: locally.
Pages with Quotes
Nature, "Briefing" 1999: "It's sink or swim as a tidal wave of data approaches" http://www.nature.com/nature/journal/v399/n6736/full/399517a0.html
AAAS Science Magazine, 1999: "Physicists and Astronomers Prepare for a Data Flood" http://www.sciencemag.org/cgi/content/full/286/5446/1840
NCSA Access Magazine: "Fascinating Magic", http://access.ncsa.uiuc.edu/Stories/higgs/higgs_3.html
Oddments
| Decoding the Voynich Manuscript with Genetic Algorithms |
| ArchiveMail - Makes a plain text file out of every message in all your Outlook folders. |
| Article on Bio Feedback electronics from Practical Electronics February 1973 (PDF) |
| A photo of CERN's ALEPH Collaboration, from March 1986 (I am standing 4th from the right, at the bottom) |
| A new element discovered: Administratium |
| The user guide for the HYPOXIA reduced Oxygen treatment machine software. |
| Software for handheld devices and mobile phones. Bofinit Corporation. |
A mathematical Rebus: SEND+MORE=MONEY. A general solver for any Rebus with up to 10 "digits".
Check out my general Rebus Solver for the Pocket PC 2002: this can solve any
Rebus with up to 8 letter words, using multiplication, division, subtraction
or addition.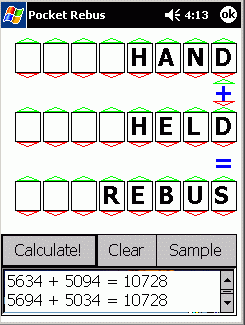 |
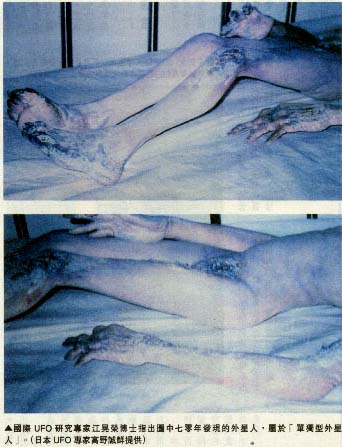
| The Roswell Alien(1), and a different view. |
| A Dictionary of Cockney Rhyming slang. |
| This photo from the early
1980s is not of me, but of an unknown person who looked exactly like me at
that time. I believe it was from a newspaper article about dropping Radio 4
broadcasts on Long Wave. It was sent to me by my friend Steve Hancock of
CERN, who captioned it amusingly. The odd thing is that I had an identical
model Grundig radio at the time. Very weird.
|
| An article in Sunset Magazine about our house in Pasadena |

Humour
TheSpoof: http://www.thespoof.com/
Java Bits and Pieces
A simple Java Mathematical
expression evaluator. Source code is HERE.
Functions supported:
*,-,/,+.sin,cos,tan,asin,acos,atan,min,max,atan2,exp,sqrt. E.g. it will
evaluate expressions like this, in double precision:java Evaluator "1+-min(-33,+4)*sin(0.5-0.1e-7) -atan2(3,4) +1/(0.051e-5)" 1+-min(-33,+4)*sin(0.5-0.1e-7)-atan2(3,4)+1/(0.051e-5) = 1960801.7782690835
|
| Code for a Kalman Filter Track Fitter, developed by JJB and Rick Wilkinson in the GIOD Project (functional but incomplete, put here because several people have asked me for it!) |
| Solving the Travelling Salesman problem, using a Genetic Algorithm |
| Track finding in a particle physics detector, using a Genetic Algorithm |
| Arild Berg sent me a link to his superb Maze Solver, that uses a Genetic Algorithm |
| A simulation of life |
| A gravitational simulation of a set of masses rotating about a fixed point |
| A simplistic Chess applet |
Of Historical Interest
| Here is a
programme of work document for
CERN's ECP/PT Group, dated August 1990, drafted by Paolo Palazzi, and containing
a contribution from (amongst others) R. Cailliau proposing a new project on
"HYPERTEXT / HYPERMEDIA". This was to later turn into the World Wide Web. Of
note is that this document pre-dates the official birth date of the world wide
web, which seems to be pinned at November 1990 ...
The PT group never really got off the ground, although I do remember a very
convivial set of meetings that took place in a good Auberge in the Jura. The
relevant section follows: "APPENDIX
C: HYPERTEXT / HYPERMEDIA R. Cailliau
- select the level of services that can reasonably be implemented and the platforms on which they would be provided, - buy all components that can be bought, - integrate, - populate. |
| 1) The "SHIFT" proposal, CERN,
July 25, 1991 "Scalable
Heterogeneous Integrated Computing Facility Testbed". Design Study and
Implementation Proposal. (PDF)
The authors are: Jean-Philippe Baud, Julian Bunn, David Foster, Frederic Hemmer,
Erik Jagel, Joop Joosten, Olivier Martin, Les Robertson, Ben Segal and Rainer
Tobbicke. 2) Cost of intrusions/hackers on CERN VAX Clusters, 1992 3) Report on trip to DEC, 1992, information on Alpha chips, GIGASwitch, and other NDA 4) Trip report from 1996, visit to MIT Media Lab, DEC sites, etc. other NDA
|
| CERN's first "Computer" ... the incredible Wim Klein. Here
is an extract (kindly provided from the CERN Archives by Miguel Marquina) from a
demonstration of
Klein in action, taken from his official retirement show at
CERN, December 10th. 1976. (There is some more
information about Wim Klein
here.)
This is an amusing story I was told about Klein. I have no idea if it's true, or not.
An HP salesman came to CERN with one of HP's very first
digital calculators, which were exciting a lot of interest in the science
community at the time The DG himself arranged a demonstration, and invited |

Code Analysis
| The Floppy and Flow User's Guide describes the use of this Fortran coding convention checker, tidier, and Fortran to HTML converter, together with information on its companion program Flow, used for making various analyses of Fortran code. You can download Floppy/Flow from Netlib. |
| An evaluation of LOGISCOPE. (old) |
| Using Logiscope to analyse various CERN codes in 1991. |
Fishy Business
| Julian and Sarah's Reef Aquarium |
Eminem
I was CTO in a company called Equate Systems, a small Los
Angeles based startup. We sold a software system I wrote called julianKeys. Most
notably this software was a featured download on Universal Music Group's Eminem
web page (Eminem Keys) at the time of release of "The EMINEM Show". You can
still download the Keys here, but they wont work fully as intended due to the
lack of server support...
http://www.eminem.com/eminemkeys/download/ . You can see an image of the
EMINEM Web Site as it appeared at that time, showing the
Eminem Keys download here. We also made
a version of JulianKeys for No Doubt. 
Various random writings
| Reply to request for a loan of network gear. |
| Hypothetical CACR Entrance Examination paper |
| Buying a Juniper Share |
| Trip report (Colorado Springs, 1993) |
| Trip report (Toronto, 1990) |
| Trip report (Venice, 1994) |
| A request Bernd Pollermann and I made in 1989 for a student to work on distributed TCP-based document access ... |
| Trip report (USA, 1988) |
Collections
| JJB's coin collection. |
| JJB's stamp collection. |
BUNN stuff (old)
| England trip 2003 |
| Bunn family photo, Sarah surrounded by Bunns |
| The Sarah and Julian England'98 Holiday Pages |
| Sarah's home page! |
| A poem by Jessica |
| The famous Bunn coffee machine company. |
| The origin of the surname Bunn. |
| A selection of pictures. |
| JJB's Potted History. |
| A delicious choice at Caltech's Athenaeum |
Technology Tracking (old)
| The LHC Computing Technology Tracking Teams. |
| A presentation made to CMS describing the mandate of the Technology Tracking Teams. |
Simulation (old)
| Simulation of proposed WAN models for tackling the LHC computing problem. |
| An evaluation of the modelling tool NETWORK II.5. (old) |
| A proposal made in 1994 on how to provide massive numbers of compute cycles for LHC simulation using PCs in the NICE system. |
| A program I wrote for the Monty Hall problem ... extract from sci.math.num-analysis |
Reviews and Reports (old)
| A paper on Collaborative Computing Environments for HEP given as a plenary talk at CHEP'97, in Berlin, April 1997. |
| A review of the CHEP '95 Conference which took place in Rio de Janeiro. |
| George Renevey's Guide to Restaurants in the Geneva area. |
HTML Converters (old)
| A tool for partially converting Windows Help files into HTML. |
| A tool for partially converting HTML into a Windows Help File. |
| A very simple plain text to HTML converter. |
| A crude converter for VAX Document to HTML. |
VMS stuff (old)
| A recipe and program for converting VMS mail to Microsoft Internet Mail. |
| The VXCERN Cluster User's Guide describes the VXCERN Cluster, and its use. |
| A presentation of possible futures for VXCERN/VXENG made in 1995. |
| A promiscuous mode Ethernet packet filter for VMS systems. |
| A VMS X Windows program for displaying points in Lyapunov space. |
| A User Friendly Interface to VMS Disk Quotas .. paper at DECUS Rome 1987 |

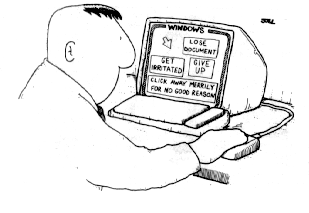 (The screen shows buttons for "Lose
Document", "Get Irritated", "Give Up", and "Click Away
Merrily for No Good Reason"!)
(The screen shows buttons for "Lose
Document", "Get Irritated", "Give Up", and "Click Away
Merrily for No Good Reason"!)

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
JJB discovers the picture grabbed with the Miro DC1 has an unhealthy blue tinge ...

(From "Whizz for Atomms" by Geoffrey Willans and Ronald Searle)