
A collaboration between: Caltech, CERN, UMichigan, UFlorida, and many others
(The above list shows those present in Tampa: many others not listed assisted from their home institutions)
The Powerpoint Animated Logos display is HERE.
CERN's Large Hadron Collider is due to begin operating in 2007, and at that time several large experiments will begin to accumulate particle collision data at continuous rates from several hundred MBytes per second, up to over a GByte per second. The data will be distributed over international networks to collaborating institutes and universities, where it will be processed and analysed by physicists and engineers engaged in the experiments. The experiment collaborations each number several thousand scientists, who are spread among hundreds of institutes situated in all World regions.
The architectures of the global computing systems that have been designed to handle these unusual computing demands comprise state-of-the-art high speed optical networks that interconnect a Grid of powerful processor and data storage systems, and a rich suite of applications and systems software to support the scientific missions of the experiments. The global systems are already in the final stages of deployment, and are being scaled to meet the required multi-Petabyte annual capability for 2007, and beyond.
In this context, we will demonstrate high speed transfers of event datasets between particle physics laboratories and universities collaborating on the ATLAS and CMS experiments at the LHC, and the BaBar experiment at SLAC's Linear Collider.
Using state of the art WAN infrastructure and Grid-based Web Services, our demonstration will involve real-time particle event analysis that requires optimized transfers of Terabyte-scale datasets. Individual 10Gbit/sec network links (lambdas) will be used to full capacity during the Challenge, and we will utilize servers and disk systems featuring the latest generation of processors, PCI-Express-based NICs, and the latest firmware (with the help of strategic partnerships with several vendors). We intend to saturate all available lambdas arriving at the Tampa show floor, in full duplex mode. During the Challenge, we will monitor the WAN performance using Caltech's MonALISA agent-based system. We will deploy analysis software that demonstrates the use of a suite of Grid-enabled Analysis tools developed at Caltech and University of Florida, and we will make use of EGEE, OSG, ATLAS and CMS data management software such as SRM, dCache, FTS, and PhEdEx. Prototypes of the latest version of parallel NFS will demonstrate high utilization of a 10Gb connection during real-time event analysis.
The use of the network will be in a realistic mixture of streams: those due to the organized transfer of multi-TeraByte event datasets, and those due to many smaller flows of physics data, absorbing the remaining capacity, in both directions on each wave. The intention is to prove the capability of the global HEP networks to support distributed physics analysis at the LHC, which will begin operating in 2007, as well as to emulate the real demands on the WAN during LHC operations. We intend to beat our SC2005 Bandwidth Challenge winning entry in which we aggregated over 150 Gbits/sec of physics dataset traffic.
The physics datasets will contain real and simulated events produced at Fermilab, Caltech, SLAC, BNL, CERN and other partner Grid Service sites including Michigan, Florida, Manchester, Rio de Janeiro (UERJ) and Sao Paulo (UNESP) in Brazil, Korea (KNU), and Japan (KEK).
Our network partners include LHCNet, Starlight, NLR, Internet2’s Abilene and HOPI, ESnet, UltraScience Net, MiLR, FLR, CENIC, Pacific Wave, UKLight, TeraGrid, Gloriad, AMPATH, RNP, ANSP and CANARIE.
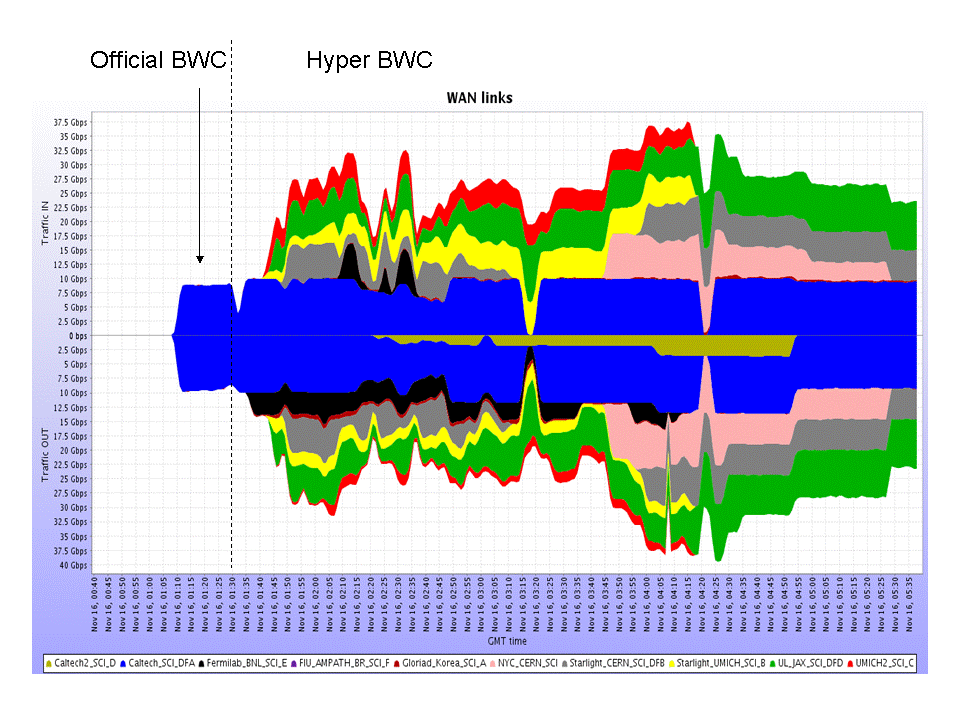
The above shows a MonALISA plot of the aggregated network traffic to the Caltech booth, during and after the Bandwidth Challenge. (The initial blue region at the left of the graph is the BWC entry.)
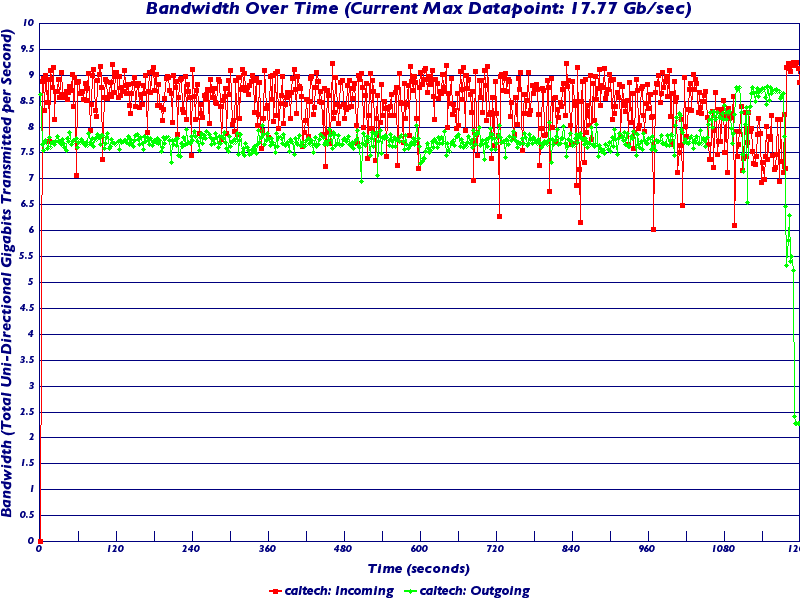
Here is the official measurement from SciNet:
Here is a set of slides from Iosif Legrand describing the results in more detail.
(Refer to Iosif's slides linked above)
"We were using a single 10 Gbps link in both directions, across the Southern Tier of the US (Tampa <--> Caltech) disk to disk. We used some loaned HP nodes with a set of laptop disks in them for reading (only good for reading) and 1U dual woodcrest nodes ("white boxes" we got for our Tier2) with 4 cheap SATA disks (320 GB, $ 95 each) for writing.
The colored stripes in the first two slides are individual node-pairs. The bottom 10 bands represent reading from SC06 and writing to Caltech. The top 8 bands are going in the other direction. Standalone a single 1U node of ours does about 230 Mbytes/sec read and 140 Mbytes/sec write with a 10G interface - it seems to be limited mainly by the disk speed. With the usual 1G ports the result (as you can see) is not far below 1 Gbps on average. I think the stability and smoothness in these plots is notable, and new.
We used a multi-threaded application FDT written by Iosif Legrand in Java using the NIO libraries and recent Linux kernels. We included the FAST TCP patch from Steven Low's group. Shawn McKee who heads the UltraLight network group and who is in the Michigan ATLAS group, did the "UltraLight kernel" based on 2.6.17(etc.) with the FAST patch, that was used.
The top plot is the official SCInet measurements of our aggregate flow, it peaks at 17.77 Gbps and was typically 16-17 Gbps.
There are no TCP instability problems evident here due the nature of FDT that fills and ships buffers in kernel space and streams the buffers through an open TCP socket (no starts and stops when sending a large set of small files), and I think also due to the equilibrium achieved by FAST. What I think is a limitation (to be confirmed) is the fact that as the traffic reaches close to 10 Gbps, the acknowledgement packets arrive in a less regular sequence since they are accompanied by a lot of other large packets. This requires more analysis. Unidirectional traffic reached a very stable 9.2 Gbps.
We will make this available as a lightweight tool for
standalone data transport. It will also help to deploy
the LISA agent of MonALISA to profile and help with
the configuration of the end systems. This will help
demystify what happens with less modern hardware
and/or configurations. For dual Opteron or Woodcrest nodes
we don't expect many problems.
For Tier1 and Tier2 production operations our group is undertaking to integrate FDT into dcache doors, working with Don Petravick's team at Fermilab. Ilya Narsky of our group has begun to look into this."



Powerpoint presentation describing Rootlets: PPT
Michael's Photographs: http://ultralight.caltech.edu/~wart/sc2006/index.html
Yang's Photographs: http://mgmt.caltech.edu/~yxia/sc2006/pictures/index.htm
Julian's Photographs:

















