 |
In late 1996, Caltech HEP (H. Newman), Caltech's Center for Advanced Computing Research (P. Messina), CERN IT Division (J.Bunn, J.May, L.Robertson), and Hewlett Packard Corp. (P.Bemis, then HP Chief Scientist) initiated a joint project on "Globally Interconnected Object Databases", to address the key issues of wide area network-distributed data access and analysis for the next generation of high energy physics experiments.
The project was spurred by (1) the advent of network-distributed Object Database Management Systems, whose architecture holds the promise of being scalable up to the multi-Petabyte range required by the LHC experiments (2) the installation of large (0.2 TIPs) computing and data handling systems at CACR as of mid-1997, and (3) the fundamental need in the HEP community to prototype Object Oriented software, databases and mass storage systems, which are at the heart of the LHC and other (e.g. BaBar) major experiments' data analysis plans, and (4) the availability of high speed networks, including ESnet, and the transatlantic link managed by our group; as well as the next generation networks (CalREN-2 in California and Internet-2 nationwide) planned to come into operation in 1998-9 with speeds comparable to those to be used by HEP in the LHC era.
A plan to understand the characteristics, limitations, and strategies for efficient data access using these new technologies was formulated by Newman and Bunn in early 1997. A central element of the plan was the development of a prototype "Regional Center". This reflects the fact that both the CMS and ATLAS Computing Technical Proposals foresee the use of a handful of such centers in addition to the main center at CERN, with distributed database "federations" linked across national and international networks. Particular attention was to be paid to how the new software would manage the caching, clustering and movement between storage media and across networks of collections of physics objects used in the analysis. In order to ensure that the project would immediately benefit the physics goals of CMS and US CMS while carrying out its technical R&D, the project also called for the use of the CACR computing and data storage systems to produce Terabyte samples of fully-simulated signal and background events (with a focus on intermediate-mass Higgs searches) to be stored in the database. The plan was agreed to by all parties by the Spring of 1997, and work officially began in June 1997.
Rapid and sustained progress has been achieved over the last two years: we have built prototype database, reconstruction, analysis and (Java3D) visualization systems. This has allowed us to test, validate and begin to develop the strategies and mechanisms that will make the implementation of massive distributed systems for data access and analysis in support of the LHC physics program possible. These systems will be dimensioned to accommodate the volume (measured in PetaBytes) and complexity of the data, the geographical spread of the institutes and the large numbers of physicists participating in each experiment. At the time of this writing the planned investigations of data storage and access methods, performance and scalability of the database, and the software development process, are all completed, or currently underway.
To do this, we have adopted several key technologies that will probably play significant roles in the LHC computing systems: OO software (C++ and Java), commercial OO database management systems (ODBMS; specifically Objectivity/DB), hierarchical storage management systems (HPSS) and fast networks (ATM LAN and OC12 regional links). The kernel of our prototype is a large (~1 Terabyte) Object database containing ~1,000,000 fully simulated LHC events. Using this database, we are investigating scalability and clustering issues in order to understand the performance of the database for physics analysis. Tests include making replicas of portions of the database, by moving objects in the WAN, executing analysis and reconstruction tasks on servers that are remote from the database, and exploring schemes for speeding up the selection of small sub-samples of events. Another series of tests involves hundreds of "client" processes simultaneously reading and/or writing to the database, in a manner similar to simultaneous use by hundreds of physicists.
Future work will include deployment and tests of the Terabyte-scale database at a few US universities and laboratories participating in the LHC program. In addition to providing a source of simulated events for evaluation of the design and discovery potential of the CMS experiment, the distributed database system will be used to explore and develop effective strategies for distributed data access and analysis at the LHC. These tests are foreseen to use local, regional (CalREN-2) and the Internet-2 backbones nationally, to explore how the distributed system will work, and which strategies are most effective.
In the following sections we describe the progress and results so far, and introduce a closely related new project on distributed LHC data analysis, MONARC, which has recently started. The GIOD Project is due to complete at the end of 1999.
GIOD uses several of the latest hardware and software systems,
We developed a simple scaling test application, and looked at the usability, efficiency and scalability of the Object Database while varying the number of objects, their location, the object selection mechanism and the database host platform.
Our results demonstrated the platform independence of both the database and the application, and the locality independence of the application. We found, as expected, significance query performance gains when objects in the database were indexed appropriately.
We are using the Caltech Exemplar as a convenient and powerful testbed for profiling the behaviour of the database with many clients under a variety of workloads.
Objectivity shows almost ideal scalability, up to 240 clients, under CMS reconstruction and data acquisition workloads. There is excellent utilization of allocated CPU resources, and reasonable to good utilisation of allocated disk resources. It should be noted that the Exemplar has a very fast internal network, which allows us to avoid the problems that would plague 1999-vintage "farms" of PCs or workstations interconnected with standard lower speed LANs. We did however, find major scalability problems in the database page server (called an "Advanced Multithreaded Server" or AMS) that we were using.
A read-ahead optimization for database objects is needed to obtain reasonable disk efficiency. Taking expected hardware developments into account, our work provides a proof-of-concept implementation, which shows that it will be possible to run all CMS full-reconstruction jobs against a single database federation containing all of the raw and reconstructed data.
We evaluated the usability and performance of Versant ODBMS, Objectivity's main competitor. Based on these tests we concluded that Versant would offer an acceptable alternative solution to Objectivity, if required.
We tested one aspect of the feasibility of wide area network (WAN)-based physics analysis by measuring replication performance between a database at CERN and one at Caltech. For these tests, an Objectivity/DB "Autonomous Partition" was created on a 2 GByte NTFS disk on one of the Pentium PCs at Caltech. This AP contained a replica of a database at CERN. At the same time, an AP was created at CERN with a replica of the same database. Then, an update of 2 kBytes was made every ten minutes to the database at CERN, so causing the replicas to be updated. The transaction times for the local and remote replications were measured over the course of one day.
The results showed that during "saturated hours", when the WAN is busy, the Time to commit the remote transaction is predictably longer than the time to commit the local transaction. On the other hand, when the WAN is quieter, the remote transaction takes no longer than the local transaction. This result demonstrates that, given enough bandwidth, databases may be transparently (and seamlessly) replicated from CERN to remote institutions.
We tested creating a federated database in HPSS-managed storage, using an NFS export to a machine running Objectivity. The results showed that the HPSS/NFS interface can indeed be used to store databases, but the performance is poor and timeouts a problem when database files need to restored to disk from tape.
We ported the data reconstruction and analysis software for the H2 detector test beam at CERN to Windows/NT. This task involved acquiring Rogue Wave Tools.h++ and installing an Objectivity/DB database of approximately 500 MBytes of raw data from CERN, previously copied across the WAN to Caltech. After initial tests with the software, it was decided to redirect all activities towards the CMSOO prototype (see below).
In early 1998, Caltech/HEP submitted a successful proposal to NPACI (The National Partnership for Advanced Computing Infrastructure) that asked for an Exemplar allocation to generate ~1,000,000 fully-simulated multi-jet QCD events. Event simulation on the Exemplar has been running since May 1998, with an accumulated total of ~1 TBytes of result data (~1,000,000 events), stored in HPSS. The physics in these data is now being studied at Caltech by S.~Shevchenko and R.~Wilkinson of our group. In addition, the events are being used as a copious source of "raw" LHC data for the GIOD Project, and are processed by the "CMSOO" application described below.
In 1998, CMS Physicists had produced several sub-detector orientated OO prototypes (e.g. for the Tracker, ECAL and HCAL detectors). These codes were mainly written in C++, occasionally with some Fortran, but without persistent objects. We took these codes and integrated them into an overall structure, redesigning and restructuring them where necessary. We then added persistency to the relevant classes, using the Objectivity/DB API. We then reviewed the code and its structure for speed, performance and effectiveness of the algorithms, and added global reconstruction aspects. These included track/ECAL cluster matching, jet finding and event tagging.
To process the simulated multi-jet data, the procedure used is to read the raw data files using the "ooZebra" utility developed in CMS, to create raw data objects (Tracker, Muon hit maps, ECAL, HCAL energy maps) for each event, and then to store these objects in an Objectivity database. The raw objects are used to reconstruct tracks and energy cluster objects. These new objects are in turn stored in the database. Finally, pattern matching algorithms create "physics" objects like Jets, Photons, Electrons, and Missing ET, which are subsequently stored in the database as "analysis objects".
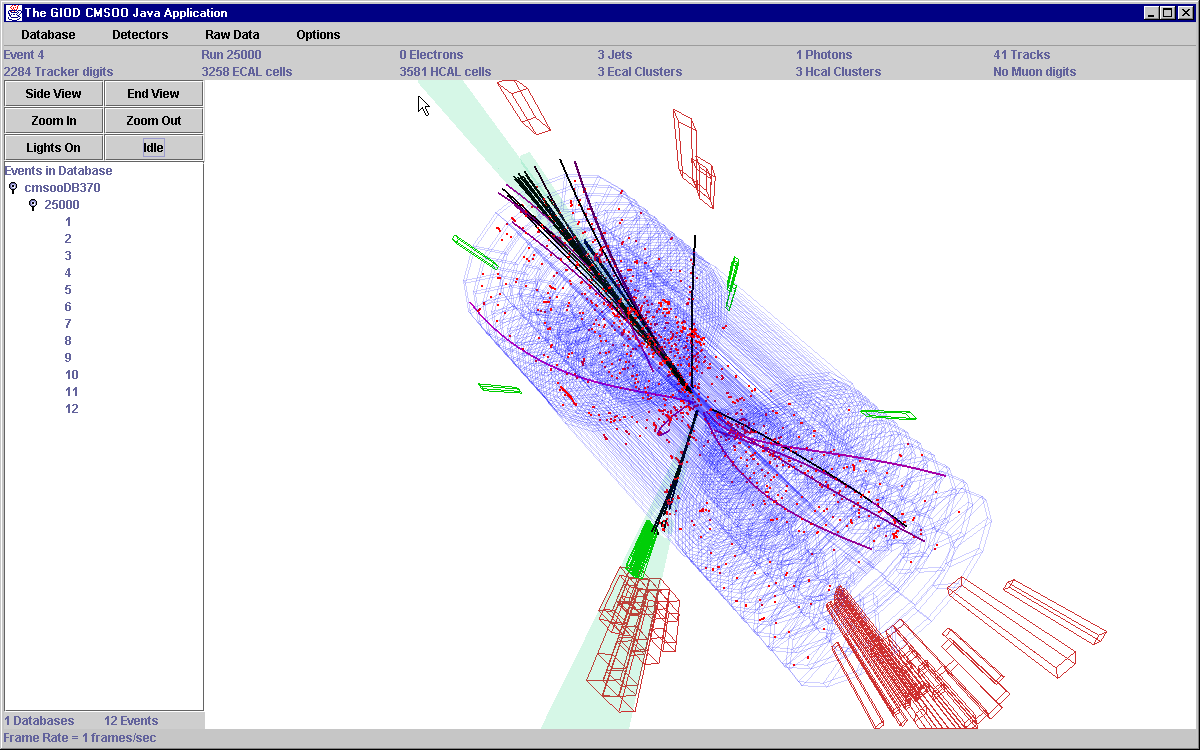
The Java API supplied with Objectivity/DB has proven to be an extremely convenient and powerful means of accessing event object data (created using the C++ CMSOO application) in the CMSOO database. We have developed a 3D event viewer, which directly fetches the CMS detector geometry, raw data, reconstructed data, and analysis data, all as objects from the database. A screen capture from the event viewer is shown in the Figure below.
|
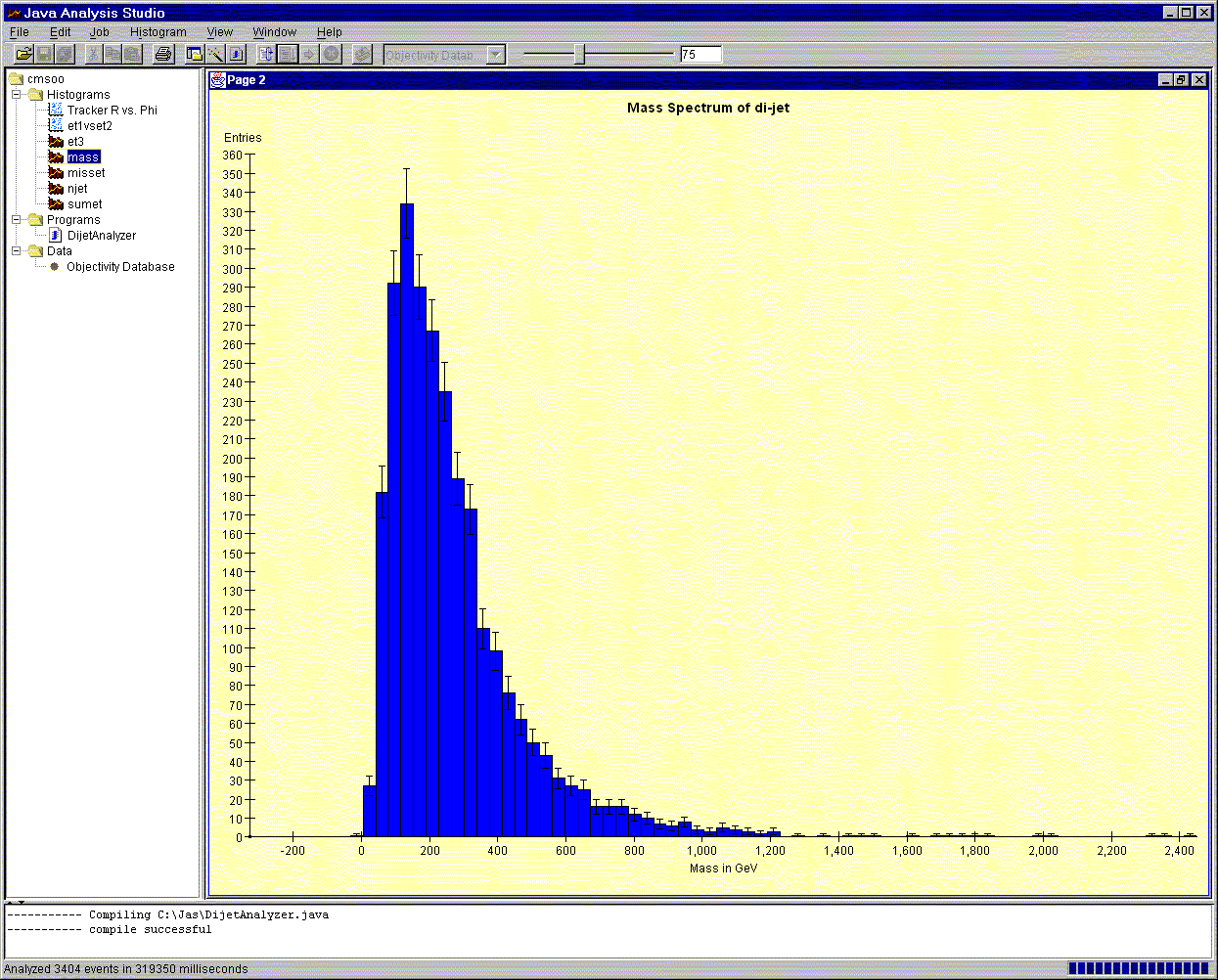
In addition, we have used SLAC's "Java Analysis Studio" (JAS) software, which offers a set of histogramming and fitting widgets, as well as various foreign data interface modules (DIMs). Using JAS, we constructed a DIM for Objectivity, and a simple di-Jet analysis routine. With the analysis routine, we were able to iterate over all events in the CMSOO database, apply cuts, and plot the di-jet mass spectrum for the surviving events. The following Figure shows the JAS di-jet mass histogram.
 |
We have also developed a demonstration track fitting code in Java, that efficiently finds and fits tracks with Pt > 1 GeV in the CMS tracker. The code identifies good tracks at a rate of ~1 per second, for a total set of ~3000 digitisings in the tracker. This compares favorably with the C++/Fortran Kalman Filter code we use in CMSOO (which also operates at about 1 track per second, but which is a considerably more compute intensive procedure).
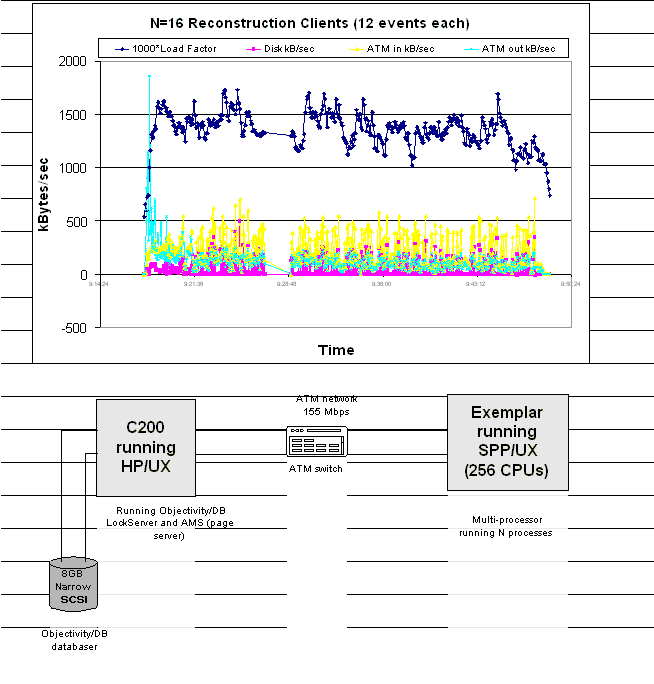
Recent work in GIOD has been focussing on the network-related aspects of using the CMSOO database. Tests have begun which involve distributing a number of database client processes on the Exemplar, and having them communicate with a database hosted remotely across a dedicated ATM fiber link on an HP C200 workstation. We have measured the I/O throughput to the disk containing the database files, the I/O traffic on the ATM network, and the load on the database host processor during the tests. At the time of writing, the test results are still being interpreted, but an initial clear conclusion is that the Objectivity database lock and page servers play important roles in governing the maximum throughput of the system.
 |
The GIOD work has resulted in the construction of a large set of fully simulated events, and these have been used to create a large OO database. The Project has demonstrated the creation of large database federations, an activity that has included practical experience with a variety of associated problems. We have developed prototype reconstruction and analysis codes that work with persistent objects in the database. We have deployed facilities and database federations as useful testbeds for Computing Model studies in the MONARC Project.
The project has proved to be an excellent vehicle for raising awareness of
the computing challenges of the next generation of particle physics
experiments, both within the HEP community, and outside in other
scientific communities. The JavaCMS event viewer was a featured demonstration at the
Internet-2 Fall Meeting 1998 in San Francisco. At this event we used an HP Kayak PC with
FX4 graphics card as the demonstration platform, a machine loaned to us by Hewlett
Packard. At the SuperComputing '98 conference, the event viewer was demonstrated at the
HP, iGrid, NCSA and CACR stands, on two HP Kayak machines dedicated by Hewlett Packard. At
the Internet2 Distributed Storage Infrastructure workshop at Chapel Hill, NC in March
1999, the GIOD Project was a featured potential application. NASA's Johnson Space Center
has invited us to speak at their Space Operations workshop at Moffat Field, CA in July
1999.
This has strengthened our relationship with Internet-2, and (together with the VRVS work) is paving the way for CERN to become a fully-fledged Internet-2 member later in 1999.
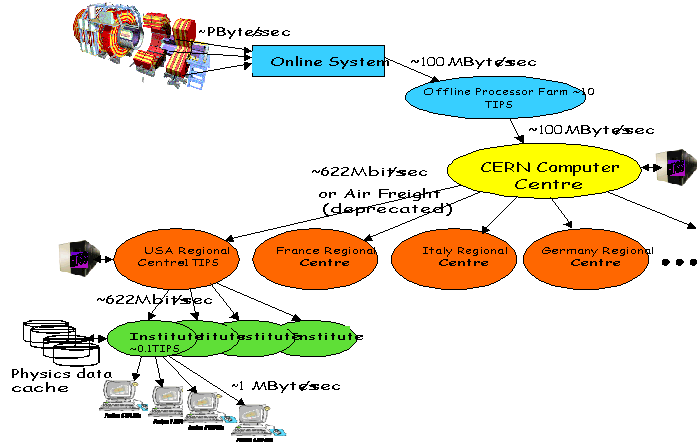
This project, entitled "Models of Networked Analysis at Regional Centres", was initiated in mid-1998 as a follow-on to GIOD, is a joint effort between Caltech, CERN, FNAL, Heidelberg, INFN, KEK, Marseilles, Munich, Orsay, Oxford and Tufts. The project is led by H.~Newman (MONARC Spokesperson, on behalf of CMS), and L.Perini (Project Leader, on behalf of ATLAS). Its main goals are to begin to define and specify the main parameters characterizing the LHC Computing Models, and to find cost-effective ways to perform data analysis on an Unprecedented scale. Working groups within MONARC have been launched that are beginning to determine feasible designs for the LHC data analysis systems. These include the design of site-architectures at Regional Centres (Architecture WG, chaired by J.~Butler of FNAL), the definition of feasible analysis strategies for the LHC Collaborations (Analysis WG, chaired by P.~Capiluppi of INFN), the construction of an evolvable simulation model of the entire distributed data analysis operation (Simulation WG, chaired by K.Sliwa of Tufts), and the implementation of a network of testbed systems to test the design concepts and the fidelity of the system simulation (Testbed WG, chaired by L.~Luminari of INFN). For example, the following Figure shows a probable scheme for distributing the CMS data to Regional Centres, and then to physicists' desktops: MONARC aims to evaluate the performance of such models, to determine a feasible set of This work will involve determining if the model is feasible (i.e. matched to the available network capacity and data handling resources, with tolerable turnaround times). Thus, MONARC intends to develop several feasible "Baseline Models" which will be used as a source of strong boundary conditions for implementation of the production LHC computing systems. MONARC will deliver a toolset for the simulation and performance verification of distributed analysis systems, to be used for ongoing design, evaluation, and further development of the Computing Models by the LHC experiments in the coming years.
 |