PASTA – The LHC Technology Tracking Team for Processors, Memory, Architectures, Storage and Tapes – Run II
Working Group (d):
Storage Management Systems
Status report – 05 July 1999 – Version 1.4
WG (d) members:
I.Augustin, J.P.Baud, R.Többicke, P.Vande Vyvre
Introduction
The PASTA WG (d) has investigated the area of (distributed) file systems, network storage and mass storage.
The investigations have been limited to the products or projects that are relevant to the computing for the LHC era in terms of capacity and performances. These products or projects have been selected on the basis of the HEP requirements. We have excluded from our study the Object-Oriented DataBase Management Systems because this technology is already being investigated by the RD45 and MONARC projects and because the file system remains the basic storage paradigm in the computing industry. The local file systems are not part of this study because they are integrated into operating systems and because the emergence of 64 bits file systems will cover the needs for the LHC era.
The first section lists some HEP requirements for distributed file systems. The second section describes the traditional distributed file systems based on the client/server paradigm. The third section describes the more recent developments in the area of file systems with the emergence of network attached storage and storage area networks.
The fourth section includes a summary of the HEP requirements for mass storage systems as expressed by a document of the Eurostore project. The fifth section is dedicated to the mass storage and hierarchical storage management systems. It includes the status of the relevant standards and a list of products.
The reference section includes web pointers to most of the companies, consortia or products mentioned in this report. These references are indicated in the text by "[ ]". The two appendices list the characteristics of the commercial products investigated in the sections on Distributed File Systems and Mass Storage Systems.
Distributed file systems
HEP requirements for distributed file systems
The concept of distributed file system has modified the way people share and distribute information. It has now become a required component for the overall experiment’s data model. This is still in evolution with the access allowed through the web. However, the distributed file system has inherent limitations, which make it unpractical, at least today, for large data transfer. The limits come from several factors: transfer cost, transfer speed, total storage capacity etc.
In summary, the distributed file system seems an ideal tool for the very wide sharing of limited amount of information such as home directories, documents or physics data at the final stage of the analysis. Whereas raw data or DSTs require a file system with better performance even if it is at the cost of less easy data access. The production stage of the experimental data processing will probably be executed in a closed environment with limited access.
The requirements of the HEP community for file systems storing moderate amount of data are similar to the requirements of other large communities such as academic, industrial or commercial organisations. These file systems must be able to support the home directories and limited file exchange in a large and geographically distributed community. It must be open, location transparent and well protected by an access control system. Some of these features are well, and sometimes better supported by the web, at least for read-only information.
Distributed file systems technologies and products
Three technologies of distributed file-systems exist today:
This report is limited to the file systems aspects of these categories. The connectivity aspects are treated by other PASTA WGs. Most of the products with a large installed base fall in the first category. SAN is an old concept (similar to the VAX/VMS cluster interconnect) that has been recently revisited. The NAS and SAN technologies are raising a lot of interest and several projects and developments are going on.
The most often used commercial products are AFS [AFS, TRANSARC], DFS [DFS], NFS [NFS], Microsoft Windows 2000 [W2000] and Novell Netware [Novell]. A detailed list of characteristics can be found in the Appendix A.
Conclusions
The future of this type of products in the PC world depends largely on the file system of W2000 that is now in Beta testing. Some of the key features of this product are known: support for distributed and large storage subsystems, usage of industrial standards such as TCP/IP or DFS, support for sites on local and wide area networks [W2000]. However, it is not yet clear if the PC products (from Windows or Novell) can scale to match the needs of our community.
Furthermore, the HEP environment is still dominated by the Unix operating systems for all the activities that are specific to physics activities (data acquisition, processing and analysis). This has been recently reinforced by the quick adoption of Linux by our community. Unless a radical change happens, it seems unlikely that Microsoft or Novell products will be the core of the physics data information system for LHC. The AFS has been and is still used extensively in the academic community. The emerging DFS system has slowed down the AFS development but has not been able to impose itself. There is today no obvious successor for AFS but the web constitutes today a good alternative for some of the needs covered now by AFS.
This issue will have to be investigated actively in the near future, taking into account the potentials of storage area networks. They will probably influence our future architecture of distributed file systems in the local area.
Storage Area Network based File Systems
The simplicity of the distributed file system interface has facilitated collaboration of dispersed groups and has modified the way people work. The limited performances of server-based distributed file systems are acceptable for wide-area network. They become a problem for local –area network and more demanding applications.
The dramatic increase of performance of local-area networks and of switching technologies has made possible faster and more scalable networks. The same performance shift is desirable for storage. Some device attachments available since few years, such as HiPPI, Fibre Channel or the IBM’s SSA, allow for better performance, scalability and sharing. Two different classes of devices can be connected on these shared file systems:
However, although the hardware is available since several years, server-less SANs are not yet available. The storage device sharing is not yet available at the application level. The difficulties of developing and marketing this technology are twofold. First it requires splitting the functionality’s of the storage device driver between the software driver and the hardware device. This implies a modification of the operating systems kernels. Second, the storage market is completely open for the two most used storage attachment standards: IDE and SCSI. Any modification of an existing standard or creation of a new one will be a long and heavy process. The issue is even more complicated by the possibility of sharing storage devices between machines running different operating systems.
Several projects are investigating these issues and some products are being developed to realise servers-less shared file systems. Here is a list of some of them:
Two consortiums are also driving the efforts in this emerging field. First, the Storage Networking Industry Association (SNIA) [SNIA] has been founded by companies from the computing industry (IBM, Compaq, Intel etc), the storage industry (Strategic Research Corporation, Crossroad Systems, Legato Systems, Seagate Software, Storage Technology Corporation) and the microelectronics industry (Symbios Logic) and counts now 98 members. SNIA's goal is to promote storage networking technology and solutions and to ensure that storage networks become efficient, complete, and trusted solutions across the IT community.
Second the Fibre Alliance [Fibre Alliance] has been formed by 12 companies (Ancor, EMC, Emulex, HP) to develop and implement standard methods for managing heterogeneous Fibre Channel-based SANs (networks of systems, connectivity equipment and computer servers). The Fibre Alliance has submitted to the Internet Engineering Task Force (IETF) the engineering Management Information Bases (MIB). It requests the IETF consider the MIB as the basis of SAN management standards.
Conclusions
The underlying technology is understood and affordable. It would have a lot of benefits to achieve a high performance, reliable and portable data sharing system. Its adoption will require agreeing on new standards and modifying the operating systems. Despite these difficulties, it will probably become available before the LHC start-up. In HEP, its applicability is much wider than distributed file systems. It would have a big impact for all the operations involving large data transfers such as central data recording or production data processing. This technology should therefore be taken into account in the future LHC computing plans.
Mass Storage Systems
HEP requirements for Mass Storage System
The user requirements for Mass Storage Systems (MSS) have been divided into "phases" corresponding to the different tasks of data recording and processing happening in a typical HEP environment. These phases are the data recording, the data processing, the analysis development and the analysis production. For all these phases, the main computing operations will be described, the consecutive requirements will be listed and the applicability of a database will be explained.
Raw Data Recording
The data recording is more and more executed by central facility available in the computing centre. The Central Data Recording (CDR) is becoming the de facto standard. Given the rapid progress of the networking technology, it is already guaranteed that this will be possible during the LHC era. This is the option that we have considered here.
In this simplistic model, the CDR can be described as a set of different data streams that are fed into the storage system continuously 24 hours a day for several months a year. Except for operational failures, these streams will not stop for any discernible period. The data will be stored in a disk buffer before it is copied to a permanent storage as soon as possible.
Traditionally the "raw data" in the permanent storage (e.g. tapes) is not overwritten during the lifetime of the experiment. It can be considered as a WORM storage class.
An essential part of the CDR is the monitoring of the performance of the experiment and the CDR itself. The experiment performance is usually checked by accessing the raw data that resides still on disk thus requiring an extended lifetime of this data. Also the readability of the data on the tapes is checked by accessing (at least part of) the permanent storage.
In parallel the independent stream of calibration data has to be stored on disk, with an additional copy to a permanent storage. This data is continuously analysed during the data taking and maybe even after that.
All these operations are executed by a specialised group of users and can be optimised.
Requirements
Database
In this phase, the files are named in a transparent way. Most of the experiments use a combination of consecutive numbering and time labels. As every file ends up in the permanent storage, a simple database is sufficient. Additional need for a database arises from time dependent parameters, like calibration and detector configurations. For this also a simple database is sufficient.
Data Processing
The raw data in the permanent storage will have to be reprocessed due to improved calibrations and reconstruction software. Therefore the bulk of data will be read and processed systematically. The resulting data will also end up in a permanent storage (e.g. tapes). Every experiment attempts to avoid these reprocessing campaigns, but previous experience show that one or two of them are likely.
Same requirements as previous phase
Database
During the processing, the "data stream" will be broken up. This means the data will be split in a set of output classes depending on their physics content. Probably the consecutive order will be lost and a more sophisticated database will be needed.
Analysis Development
In contrast to the previous stages, which are co-ordinated efforts of a few users, this one comprises up to several hundred users who attempt to access data in an uncontrolled way (quotas will be a topic). Each of them probably accesses of the order of ten GB in each job. Here a sophisticated staging system is required. The amount of output is small compared to the amount of input data, but has to be backed up. The external participants probably want to export data (~ nTB/institute, ~100 Institutes) to their computing facilities. This eases the load on the central systems but requires export services.
Requirements
Database
Additional to the processed data files, the outputs of the various analyses have to be managed by the storage system. A priori it is not determined whether the data produced by the previous stages is maintained by the same storage system. This strongly depends on the actual hardware configuration. Even if the users analyse their data on remote machines, the access to the processed data files has to be centrally controlled.
Analysis Production
In theory, every physics analysis of a user leads to a systematic analysis of a big fraction of the data. In practice, a lot of work is redundant and analyses are only done on data already preselected at the data processing stage. This phase strongly depends on the experiment’s data organisation, physics goals and requirements.
Same requirements as previous phase
Database
The organisation of the results of the systematic analysis of all the relevant data is unknown. This strongly depends on the experiment. As these results are the final ones it is likely that the experiment wants to store them centrally.
General Requirements
There are several requirements that are common to all phases:
Summary of requirements
The central data recording and the data processing can be viewed as relatively static environments. In the first case, the most important fact is the uninterrupted storage of data onto a permanent storage medium. The data rate is predictable and quite constant for a long period. The lack of human operators requires a stable and reliable system. Dynamic allocation of resources normally only happens in case of a failure in the system (e.g. tape drive). The data processing is, in principle, quite similar with slightly relaxed requirements on the continuous operation.
The challenge changes in the analysis phases. The access pattern to the data becomes unpredictable and the need for a sophisticated data and resource management (e.g. disk space, staging) arises. Backup requests, file management and the limited number of resources indicate the need for a full storage system.
Mass Storage Standards
The IEEE Storage System Standards Working (SSSWG) (Project 1244) [IEEE] has developed a Mass Storage Reference Model. Several releases of this model have been issued, the last one being the Version 5 in 1994. This is now known as the IEEE Reference Model for Open Storage Systems Interconnection (OSSI - IEEE P1244). This model provides the framework for a series of standards for application and user interfaces to open storage systems:
This set of standards is still under discussion and there is today no product that covers the whole OSSI. Instead some products have used part of the standard as a basis for their architecture. The standard has not followed the most recent technical development such as the SAN. Parts of the standard, such as the data mover, may therefore become quickly obsolete if they are not updated to take into account these developments.
The evolution of the OSSI proposed standard and its practical influence on the market is also unclear. The standard will probably not be ready before 2000 and maybe even later. It leaves a very short time to have standards conforming, or at least influenced products available by the start of the LHC.
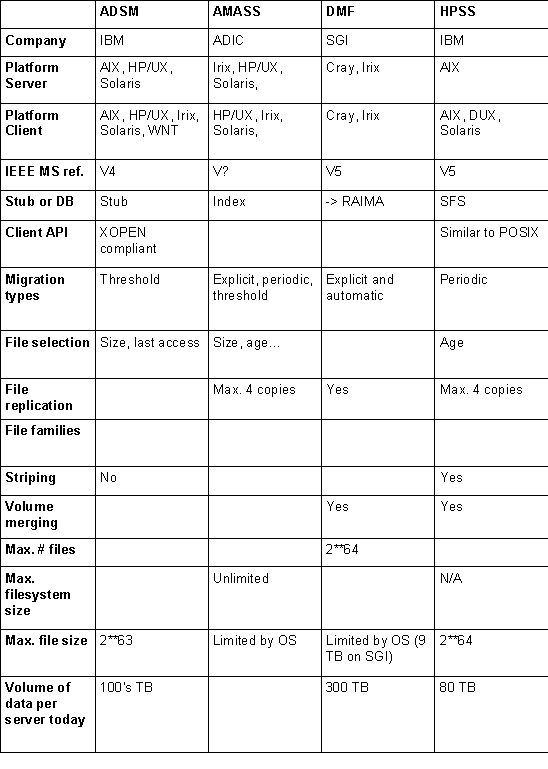
Mass Storage Products
The most often used commercial products are ADSM/IBM [ADSM], AMASS/Raytheon E-Systems [AMASS], DMF/SGI [DMF], EuroStore [EuroStore], HPSS [HPSS] and SAM-FS/LSC [SAM-FS].
Their main characteristics are summarised in the Table 1 (a) and (b). A detailed list of features can be found in the Appendix B.
These systems use real file systems, while HPSS uses a name server.
The MSS system delivered by the EuroStore project might result in a commercial product supported by QSW and/or a non-commercial product supported by DESY. These two options are shown in the Table 1 (b).
Conclusions
The reference standard for mass storage systems is the IEEE Reference Model for Open Storage Systems Interconnection. Its development has been very long and it is evolving very slowly. Several products conform to the model or part of it but none has implemented it. In addition, the standard does not specify the interface between the various components. Therefore, the interoperability between different systems will most probably remain a dream and the conformance to the standard is not a key issue.
The issue of portability of applications to another MSS or another computer platform is therefore critical. Even more dramatic is the issue of moving bulk amount of data from one system to another. The data recorded by one MSS might not be readable by another one. Given the duration of the LHC project, it is probable that at least one change of MSS will be done during the whole project lifetime.
The market of mass storage systems is relatively limited and the future of these products and of these companies seems often unclear. They target needs (backup or dynamic tape space management) that are relatively different and more complex than ours are but some of these products could be and are sometimes used for physics data management. The questions of their cost of buying and ownership, their complexity, their portability and their future have to be addressed.
Given all the previous considerations, different home-made systems are being developed to address the needs of HEP. This is the case of CASTOR [CASTOR] at CERN,
ENSTORE [ENSTORE] at Fermilab and the EuroStore MSS [EuroStore] at DESY. These are certainly good alternatives that should be pursued before a decision is taken for the LHC. The questions of their development cost and long-term maintenance should also be addressed.
Table 1 (a): Comparison of the Mass Storage products.
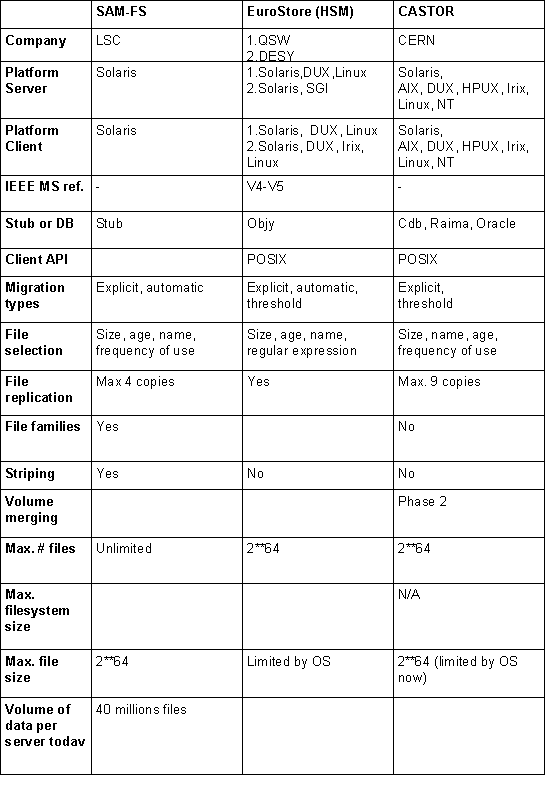
Table 1 (b): Comparison of the Mass Storage products.
References
ADSM
ADSM-HSM White Paper at
ADSM-HPSS comparison at
http://www.storage.ibm.com/software/adsm/adwhhpss.htmlAFS:
http://www.transarc.com/Support/faqs/afs.faq.html
http://www.transarc.com/Product/EFS/AFS/afstonfs.htmlAIIM
http://ses2.ses-inc.com/~joelw/TAPE_FMT/MS66V11.html
AMASS
http://www.adic.com/US/English/Products/Software/
CASTOR
CDNA
http://www.datadirectnetworks.com/English/Technology/CDNA/workgroups.htm
Coda
DFS
:http://www.transarc.com/Product/EFS/index.html
http://www.hp.com/pressrel/apr97/15apr97g.htmhttp://www.digital.com/info/dce
http://www.transarc.com/Product/EFS/DFS/Seybold/dfssey.html
DMF
EMASS
ENSTORE
EuroStore
http://www.cern.ch/eurostore/
Fibre Alliance
http://www.emc.com/fibrealliance/
GFS
:HPSS
:http://www.sdsc.edu/hpss/hpss.html
http://www5.clearlake.ibm.com:6001IEEE
: http://www.ssswg.org/NAStore
: http://chuck.nas.nasa.gov/Projects/3.0.0/NFS
http://www.sun.com/software/white-papers/wp-nfs/
Novell
http://www.novell.com/advantage/file/
OpenVault
SAM-FS
Store X
http://java.sun.com/products/storex
SNIA
Transarc
W2000
http://www.microsoft.com/windows/server/
Appendix A : Distributed file systems products
AFS
Coding limits
Supposedly there is a factor 2 margin in some of those limits (using 32 unsigned numbers) by trivial fixes to the code.
AFS uses a 1-level lookup to resolve the location of data from the name (volume ID) -> server/partition:
Architectural limits
Management issues
There are very few built-in administrative tools in AFS. However, similar to its close relative DFS, the system has been designed sufficiently flexible to allow operating a service with thousands users and millions of files on a around-the-clock basis without downtime for reconfigurations. The key concepts here are "mount points" used to build the AFS namespace out of smaller, manageable objects which are referenced by name only, and the "volume" abstraction which implements the physical handling of data independent of operating system or hardware characteristics.
The supplied tools only allow to make use of the offered flexibility on a relatively high "scriptable" level, a management strategy has to be implemented on top of that. It has thus been possible to automate all basic disk space administration (allocation, balancing) and push out the remaining high level decisions to the user groups themselves without the need for extensive training or dedicated administrators.
Caching
AFS uses disk caching to improve performance for file accesses. Files are cached in configurable pieces (typically 64KB) which are maintained in a consistent state, modifications to a file are automatically signalled to all clients holding a copy.
Unix/Windows interoperability
DFS
DFS is part of the Open Software Foundation’s DCE. However, OSF does not sell any DFS product. DFS for Solaris is available from Transarc, DFS for AIX from IBM. Both are full-featured DFS implementations. HP offers an enhanced version of DFS called "EFS", which works also for Windows/NT. As to Digital (Compaq)’s DCE it seems that the DFS server part does not provide the full DFS functionality (e.g. ACLs, aggregates).
The DFS architecture is very similar to AFS – the main difference is that DFS makes use of DCE transport, security and directory functionality instead of providing it’s own mechanism.
Management issues
The DFS architecture is very similar to AFS, offering the similar flexibility to extend the basic system with some suitable management framework.
Caching
File caching in implemented similarly to AFS with extensions allowing for partial file locking.
Unix/Windows interoperability
NFS
NFS is a Unix software layer on top of TCP/IP that allows sharing of data volumes between different machines. It is supported on most of the operating systems used in our environment. It supports the sharing of the same volume between different platforms. NFS is used extensively in our community.
It is used in the online dataflow of some experiments and has proven to have good performances.
Windows NT 4 (with Microsoft’s Dfs)
Windows 2000 will replace NT 4 – however W2000 is largely unknown yet. Straight extrapolation from NT4 features may not always be valid.
Architectural limits
Management issues
Windows networking is mainly a continued development of Microsoft's Lan Manager technology that allows clients to access files on other Windows machines similar to NFS. In that scheme the path name of a file always contains a reference to the server and share on which it is located.
Location independence, an essential part for round-the-clock operation, is achieved through a "Dfs" tree, a special "share" that translates path names to absolute references. With a growing number of "shares" this tree threatens, in the absence of efficient caching, to become a performance bottleneck and, since it cannot be replicated, a single point of failure.
Caching
Windows does not support any other caching then operating system buffers. Connections to file servers are state-full, the file server keeps track of open files and ensures locking. This has implications: server downtime will affect even "inactive" clients with e.g. open applications.
Unix/Windows interoperability
Netware
Architectural limits
Management issues
Might partially be addressed by Network Directory Services (NDS).
Unix/Windows interoperability
Appendix B : Mass Storage products
ADSM/IBM
AMASS/Raytheon E-Systems
DMF/SGI
SAM-FS/LSC
HPSS
OpenVault