"Bandwidth Gluttony - Distributed Grid-Enabled Particle Physics Event Analysis"
A demonstration at the iGrid2002 Conference
Primary Contacts: Julian Bunn and Bill Allcock
Argonne: William E. Allcock (allcock@mcs.anl.gov) John Bresnahan (bresnaha@mcs.anl.gov) Joe Link () Joe Insley()
Caltech: Julian Bunn (julian@cacr.caltech.edu) Iosif Legrand (Iosif.Legrand@cern.ch) Harvey Newman (newman@hep.caltech.edu) Steven Low (slow@caltech.edu) Sylvain Ravot (Sylvain.Ravot@cern.ch) Conrad Steenberg (conrad@hep.caltech.edu) Suresh Singh (suresh@cacr.caltech.edu)
DataTAG: Jean-Philippe Flatin (J.P.Flatin@cern.ch)
Description
Using distributed databases at Argonne, Caltech, CERN, possibly UCSD and other HEP institutes, we will show a particle physics analysis application that issues requests for remote virtual data collections, causing these to be moved across the WAN using both striped and standard GridFTP servers. As the collections are instantiated on the client machine in Amsterdam, the analysis results are rendered in real time. This scheme is a preview of a general "Grid Enabled Analysis Environment" that is being developed for CERN's LHC experiments.
Background
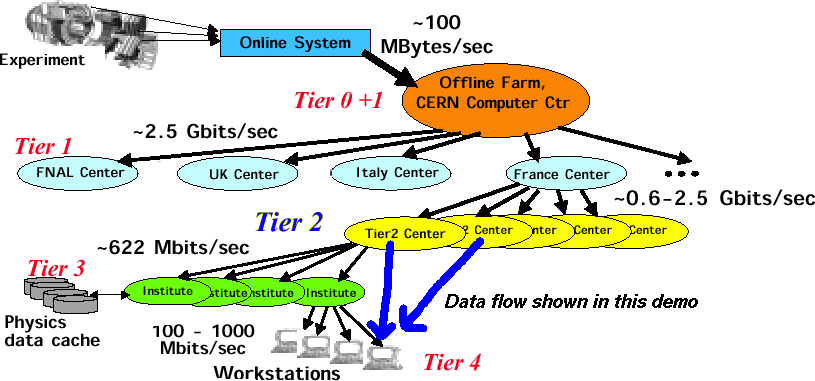
The European Nuclear Research Center (CERN) will be bringing the Large Hadron Collider (LHC), the most powerful accelerator in the world, on line in 2006. This system is projected to produce 20 Petabytes of data per year. To handle such large volumes of data, the High Energy Physics (HEP) community is proposing a multi-level or tiered distributed computing system. Tier 0 is CERN and will ultimately hold all raw and reconstructed data for the project. Tier 1 sites are national level, Tier 2 are large universities, Tier 3 are smaller universities, and Tier 4 is the individual researchers. Any data produced at a lower tier, such as analysis results and Monte Carlo simulations, will frequently need to be pushed up to higher levels.
The Globus Project has made extensions to the existing FTP protocol to add security, improved performance, and reliability. This development is called GridFTP. This has been proposed as the lingua franca for transport on the Grid. The HEP community is using GridFTP as part of the LHC project.
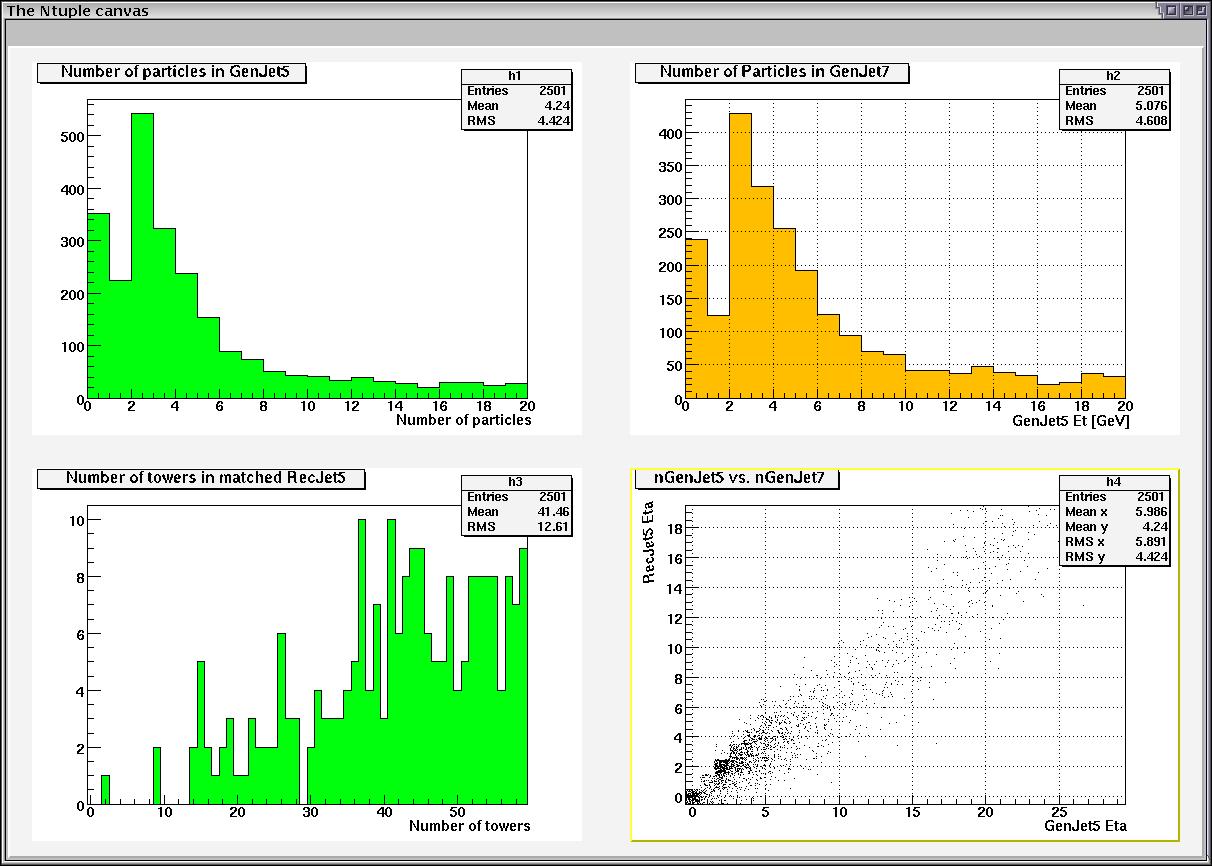
Here is a screenshot taken during iGrid2002, showing the ROOT screen while the data files are being downloaded from the remote sites:
Hardware/Software/Networking
The client hardware on the show floor will consist of an 8 node portable cluster. Each node in the cluster is a 2U Compaq DL380G2 server with 1.13 GHz PIII, 512MB RAM, and 6x36GB SCSI hard drives with onboard HW RAID, using RAID 0, dual redundant power supplies, and redundant cooling fans. The node is mounted in a shock mounted case with casters, along with KVM, 1U LCD screen and keyboard for local maintenance, and BayTech network accessible power controllers for remote power cycling, should that be necessary.

Six of the eight nodes in the cluster has a SysKonnect 9821 copper Gigabit NIC. The other two (one of which is the "mayor" or head node) have SysKonnect 9822 dual port copper Gigabit NIC's. These are connected to an Extreme 5i switch, which is a 16 port Layer 3 capable switch rated to be a non-blocking line speed switch. The switch has 12 copper ports, and 4 GBIC ports. During the show, each switch will be connected to our booth router, a Black Diamond on loan from Extreme via (2) Gigabit Fiber uplinks. Our booth router will be connected to the iGrid showfloor network via (4) 1 Gigabit fiber drops. We traveled multiple networks from there to the various sites, but most traffic came across Abilene, ESNet, and Startap.
The client application running on the cluster will initiate GridFTP transfers of ROOT data files from servers at Argonne, Caltech, CERN and possibly UCLA and Rio de Janeiro. The client application is ROOT with Clarens modifications. The ROOT data files are simulated JETMET data from the CMS Experiment at CERN.
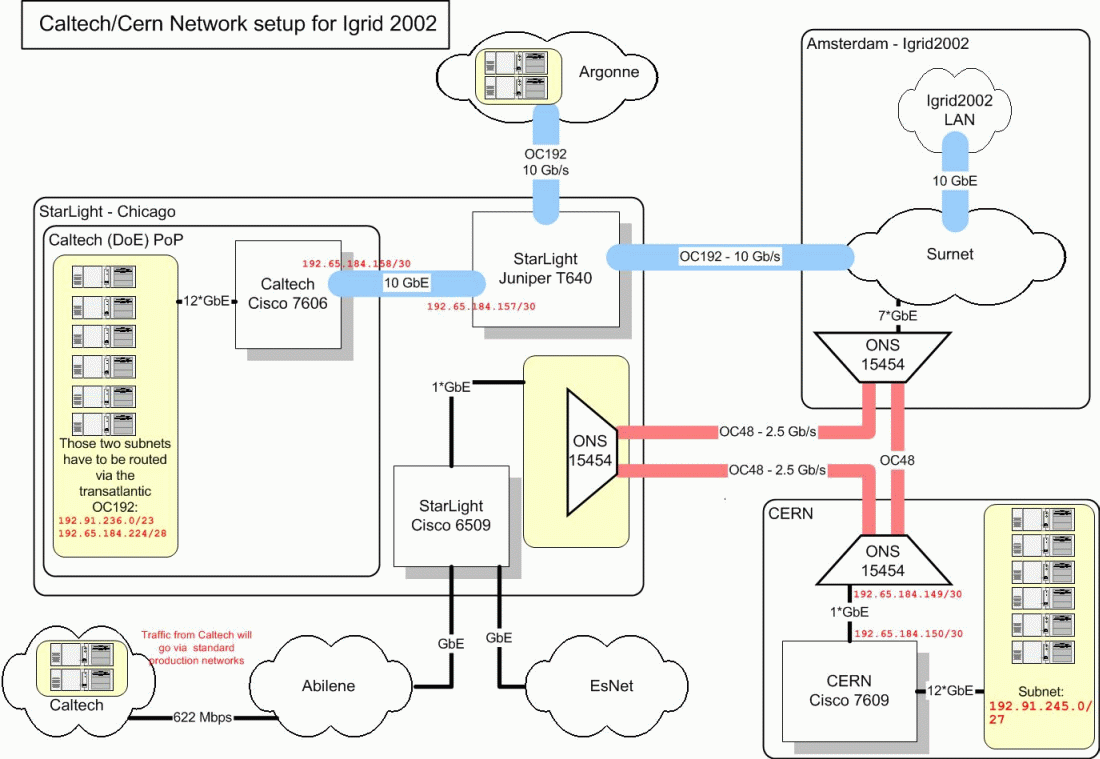
The following diagram shows the international network setup currently envisaged:
Striped GridFTP Serve at Argonne
The Argonne server is a load balancing GridFTP
proxy server. It allows a system to provide a single point of contact that
harnesses the network resources of any number of GridFTP servers. The
architecture consists of a single frontend that listens on a TCP port, and
manages client connections. As clients make requests for file transfers the
frontend selects the appropriate backend server for the job, based on resource
load and availability, and forwards the request to the selected server. All
though the backend servers may exist anywhere that the frontend server can make
a TCP connection to, it is most reasonable to have all nodes in the system on a
local area network.
Frontend
The main function of the frontend server is as a resource manager. All clients
access the system by connecting to the frontend server. Once connected clients
can send any command in the GridFTP RFC. Most commands are handled entirely by
the frontend server. The only time correspondence with a backend server occurs
is when a client requests to store or retrieve a file.
The file system
In order to understand how GPFTPD handles requests to store or retrieve files
the GPFTPD file system used must be understood. The file system is built on top
of any standard unix file system. The frontend server has files containing meta
data pointing to the backend server that contains files with the actual data.
All nodes in a GPFTPD system (both frontend and backend) must have a mounted
file system (for performance local disk space is highly recommended), with a
directory exclusive set aside to be the root directory for that nodes GPFTPD
files system (this will be referred to as the gpftpd home directory). The path
to this directory does not need to be the same on all nodes.
Under each nodes home directory GPFTPD mirrors all the sub directories. While
every node has an identical directory structure, the files within each directory
are not mirrored. In fact it is specifically forbidden for any two backend
servers to own a file with the same name and path. In other words the name space
for the GPFTPD file system is global to all backend nodes.
The frontend server has a replica file for each file on every backend node, only
each file contains meta data on the backend server location of the data file. It
uses its file system as a data base containing file size, group and user
ownership, and most importantly, the backend host and port to contact to
retrieve this data. This is further concept explored as file retrieval is
explained.
Data transfer
When data is transferred from the GPFTPD system it flows directly from the
backend server to the client. It does not need to be routed through the frontend
server. This is possible due to the FTPs third party transfer. When a client
requests a file transfer, the frontend server manipulates the commands to
initiate a third part transfer between the client and one of the backend
servers.
Storing
When a client requests to store a file the frontend server must choose a backend
server where the file will be stored. In the SC2001 demonstration this decision
was solely based on load. A list of the backend servers available to the system
is kept by the frontend. The list is ordered by how busy (how many transfers it
is currently performing) each backend server is. The least busy server is
selected. Since the goal was high performance data transfer, this was a logical
method.
Retrieving
When a client requests a file from the system the frontend must chose a backend
to do the work. Since GPFTPD does not tunnel data through the frontend server,
the frontend must select the backend where the data physically resides. It does
this by reading the host/port information from the meta data contained in the
file by the same name in it local file system. Once the host is determined the
frontend initiates a third party transfer between the client and that backend
server.
Tier2 Center at Caltech
The Caltech Tier2 server is built from a variety of 2U and 1U rack-mounted slave nodes based on PIII and Athlon processors, connected over a private LAN via Gbit uplinks to two servers with substantial (over 4 TBytes) disk arrays, which are in turn connected via Gbit fibre links to CalREN2 and from there to Abilene. More details on the Caltech Tier2 are available.

Networks and Coordination
- the US-CERN link: dedicated OC48 between StarLight and CERN Contacts Sylvian Ravot (Caltech); Olivier Martin (CERN); Tom de Fanti (Starlight)
- Abilene for links to Caltech using Gigabit Ethernet Contacts: Steve Corbato, Guy Almes (Internet2)
- CALREN peering at the L.A. downtown POPs, Contact: Tom West
- metro dark fiber or CALREN from the LA POP to Caltech. Contacts: James Patton, John Dundas (Caltech)